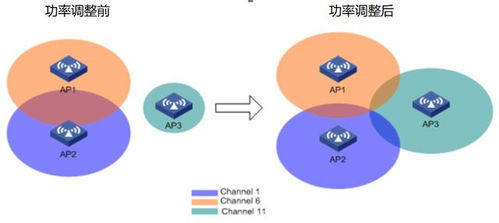
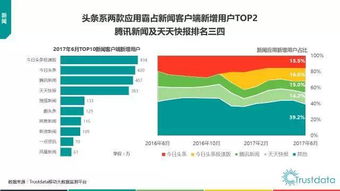
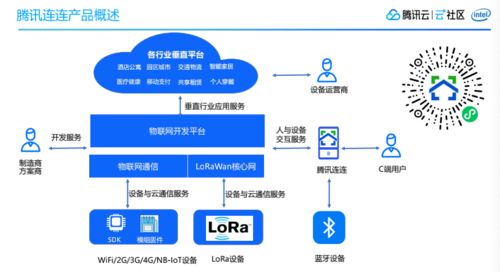
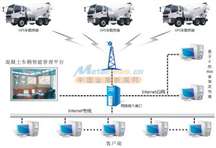
隨著科學計算、人工智能和大數據分析等領域的飛速發展,對計算能力的需求呈現指數級增長。單個計算節點已無法滿足巨量并行任務的需求,因此,由成百上千甚至更多節點協同工作的高性能計算集群應運而生。而在集群系統中,負責連接所有計算節點、存儲設備,并確保數據高效、可靠流通的網絡,是決定整個集群性能與效率的基石。高性能計算集群網絡技術的開發,正是聚焦于構建這一核心神經系統。
高性能計算網絡與傳統數據中心網絡存在顯著區別。其核心設計目標是極低的延遲和極高的帶寬,以滿足大規模并行計算中頻繁的進程間通信需求。例如,在氣象模擬或分子動力學仿真中,數以萬計的進程需要同步交換中間數據,網絡延遲的細微增加都可能被放大,導致整體計算時間大幅延長。因此,HPC網絡技術開發的首要挑戰是突破傳統網絡協議棧(如TCP/IP)的開銷瓶頸。
目前,主流的HPC網絡技術圍繞專用互連架構展開,主要包括:
- InfiniBand:作為高性能計算領域的霸主,InfiniBand通過提供遠程直接內存訪問、內核旁路等技術,實現了極低的通信延遲和極高的吞吐量。其開發重點在于不斷提升單端口帶寬(目前已達400Gb/s及以上)、增強網絡管理軟件以及對新應用模式(如異構計算)的支持。
- Omni-Path Architecture:英特爾推出的OPA旨在與InfiniBand競爭,它提供了類似的性能特性,并在可擴展性和成本方面進行了優化設計。其技術開發側重于與英特爾處理器及軟件的深度集成。
- 高性能以太網:隨著RoCE和iWARP等技術的成熟,基于以太網的RDMA正在侵蝕傳統HPC網絡市場。它允許在熟悉的以太網基礎設施上獲得接近InfiniBand的性能,大幅降低了部署和運維門檻。開發焦點在于完善擁塞控制、提升大規模部署下的穩定性以及與云環境的融合。
- 定制化互連技術:在頂尖的超算系統中,如富士通的Tofu互連D用于“富岳”,或Cray的Slingshot技術,這些定制網絡與計算架構緊密結合,實現了極致的優化。其開發是高度定制化的系統級工程。
網絡技術的開發不僅限于硬件。軟件棧,特別是通信庫,發揮著至關重要的作用。MPI作為HPC并行編程的事實標準,其網絡層實現必須與底層硬件深度協同,以充分發揮硬件能力。開發更智能的通信調度算法、支持新的編程模型(如PGAS),以及優化集體操作(如Allreduce)的性能,是軟件層面的核心課題。隨著計算與存儲的融合,支持并行文件系統的高性能數據訪問網絡也成為開發重點。
HPC網絡技術開發面臨幾大趨勢與挑戰:
- 異構計算支持:集群中GPU、FPGA等加速器日益普及,網絡需要提供GPU Direct RDMA等技術,實現加速器內存之間的直接數據交換,避免不必要的CPU拷貝開銷。
- 可擴展性與成本平衡:如何在數萬乃至百萬節點規模下保持低延遲和高帶寬,同時控制成本和功耗,是持續性的挑戰。
- 與云和人工智能的融合:公有云開始提供HPC服務,AI訓練對通信模式提出了新要求(如參數服務器、All-Reduce),網絡技術需要適應這些混合負載。
- 智能網絡操作:利用AI進行網絡性能預測、故障診斷和自動優化,是實現高效運維的下一代方向。
高性能計算集群網絡技術的開發是一個硬件與軟件深度協同、持續追求極致性能與效率的前沿領域。它不僅是連接計算節點的電纜,更是釋放集群巨算力的關鍵使能器,其進步將直接推動科學研究與工程創新的邊界不斷拓展。